引用标准库时,用尖括号(<>)
引用自己写的库时,用引号(“”)
延伸文件名(extension file name)不一定是.h或.cpp,也可能是.hpp或其他甚至无扩展名。
头文件防护式声明
complex.h
1
2
3
4
5
6
7
8
| #ifndef __COMPLEX__
#define __COMPLEX__
...
#endif
|
可以防止重复include这个库
头文件的布局
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| #ifndef __COMPLEX__
#define __COMPLEX__
#include <cmath>
class ostream;
class complex;
complex&
__doapl (complex* ths, const complex& r);
class complex
{
...
};
complex::function ...
#endif
|
class的声明
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| class complex
{
public:
complex (double r=0,double i=0)
: re(r),im(i)
{ }
complex& operator += (const complex&);
double real () const {return re;}
double imag () const {return im;}
private:
double re,im;
friend complex& __doapl (complex*, const complex&);
};
|
对于不同类型数据的需求,使用模板写class
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| template<typename T>
class complex
{
public:
complex (T r=0,T i=0)
: re(r),im(i)
{ }
complex& operator += (const complex&);
T real () const {return re;}
T imag () const {return im;}
private:
T re,im;
friend complex& __doapl (complex*, const complex&);
};
|
使用方法
1
2
3
4
5
6
| {
complex<double> c1(2.5,1.5);
complex<int> c2(2,6);
...
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| class complex
{
public:
complex (double r=0,double i=0)
: re(r),im(i)
{ }
complex& operator += (const complex&);
double real () const {return re;}
double imag () const {return im;}
private:
double re,im;
friend complex& __doapl (complex*, const complex&);
};
|
inline(内联)函数
更快,有些函数不可以,因为编译器做不到(有些太复杂)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| class complex
{
public:
complex (double r=0,double i=0)
: re(r),im(i)
{ }
complex& operator += (const complex&);
double real () const {return re;}
double imag () const {return im;}
private:
double re,im;
friend complex& __doapl (complex*, const complex&);
};
|
例
1
2
3
4
5
| inline double
imag(const complex& x)
{
return x.imag();
}
|
access level(访问级别)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| class complex
{
public:
complex (double r=0,double i=0)
: re(r),im(i)
{ }
complex& operator += (const complex&);
double real () const {return re;}
double imag () const {return im;}
private:
double re,im;
friend complex& __doapl (complex*, const complex&);
};
|
使用方法
1
2
3
4
5
| {
complex c1(2,1) complex c1(2,1)
cout << c1.re; cout << c1.real();
cout <<c1.im; cout << c1.imag();
} }
|
构造函数
在创建对象时,会自动调用该函数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| class complex
{
public:
complex (double r=0,double i=0)
: re(r),im(i)
{ }
complex& operator += (const complex&);
double real () const {return re;}
double imag () const {return im;}
private:
double re,im;
friend complex& __doapl (complex*, const complex&);
};
|
1
2
3
4
5
6
| {
complex c1(2,1);
complex c2();
complex* p = new complex(4);
...
}
|
构造函数可以有很多个,overloading重载
常用于构造函数,重载函数虽然同名,但对与编译器来说有区别
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| class complex
{
public:
complex (double r=0,double i=0)
: re(r),im(i)
{ }
complex& operator += (const complex&);
double real () const {return re;}
double imag () const {return im;}
private:
double re,im;
friend complex& __doapl (complex*, const complex&);
};
|
把构造函数放在private里
当需要不能创建对象的类时,这样写
里面有一个对象(只有一个)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| class A{
public:
static A& getInstance();
setup(){...}
private:
A();
A(const A& rhs);
...
};
A& A::getInstance()
{
static A a;
return a;
}
|
外部使用方法
1
| A::getInstance().setup();
|
常量成员函数
函数不会改变数据的,加上const
1
2
3
4
5
6
7
8
9
10
11
12
13
| class complex
{
public:
complex (double r=0, double i=0)
:re(r),im(i)
{}
complex& operator += (const complex&);
double real () const {return re;}
double imag() const {return im;}
private:
double re, im;
friend complex& __doapl (complex*,const cpmplex&);
};
|
使用者所写
1
2
3
4
5
| {
const complex c1(2,1);
cout<<c1.real();
cout<<c1.imag();
}
|
如果定义函数时没有写const,在调用时编译器就会报错
参数传递 pass by value vs pass by reference (to const)
传内容 ,和传引用的区别
传内容整个的全都传过去,传引用只传四个字节的指针
对于内容较长的参数,传引用比传内容快
为了满足传递引用,且不修改引用的内容,有时在传递引用时加上const
若是函数修改参数,编译器会报错
下面是例子
1
2
3
4
5
6
7
8
9
10
11
12
13
| class complex
{
public:
complex (double r=0,double i=0)
:re(r),im(i)
{}
complex& operator +=(const complex&);
double real ()const {return re;}
double imag ()const {return im;}
private:
double re,im;
friend complex& __doapl (complex*,const complex&);
};
|
1
2
3
4
5
6
| ostream&
operator <<(ostream& os,const complex& x)
{
return '('<<real(x)<<','
<<imag(x)<<')';
}
|
同样返回值传递也有两种:return by value vs return by reference(to const)
friend(友元)
上面的friend函数定义
1
2
3
4
5
6
7
| inline complex&
__doapl (complex* ths,const complex& r)
{
ths->re+=r.re;
ths->im+=r.im;
return *ths;
}
|
相同class的各个objects互为friends(友元)
1
2
3
4
5
6
7
8
9
10
11
| class complex
{
public:
complex (double r=0,double i=0)
:re(r),im(i)
{}
int func(const complex& param)
{return param.re+param.im;}
private:
double re,im;
};
|
1
2
3
4
5
6
| {
complex c1(2,1);
complex c2;
c2.func(c1);
}
|
回顾一下
在写一个类时会注意哪些地方
- 数据放在private里
- 参数尽可能是以refrence来传,看情况加const
- 返回值也尽量以refrence来传,不行的情况不用(下面说)
- 在类的body里要加const的就应该加上,不然使用者使用时会很麻烦,他会埋怨你
- 构造函数有一个特殊的语法是initialization list(参数初始化表)
class body外的各种定义(definitions)
什么情况下可以pass by reference
什么情况下可以return by reference
1
2
3
4
5
6
7
8
9
10
11
12
| inline complex&
__doapl (complex* ths,const complex& r)
{
ths->re+=r.re;
ths->im+=r.im;
return *ths;
}
inline complex&
complex::operator += (const complex& r)
{
return __dopal (this ,r);
}
|
先说不能return by refrence的情况
当使用的函数创建了一个新的内容,这时返回一个新内容的引用,在函数结束时,这个新内容就死亡了,这时引用里的内容也就死亡了,在去看时看到的不是想要的东西。
operator overlaoding (操作符重载之一,成员函数)this
1
2
3
4
5
| {
complex c1(2,1);
complex c2(5);
c2+=c1;
}
|
1
2
3
4
5
6
7
8
9
10
11
12
| inline complex&
__doapl(complex* ths, const complex& r)
{
ths->re +=r.re;
ths->im +=r.im;
return *ths;
}
inline complex&
complex::opeartor += (const complex& r)
{
return __doapl (this ,r);
}
|
这里写了两个函数,先跳到重载函数,重载函数的返回地址是__doapl函数,这样写的目的可能是其他函数也用到右边加到左边的操作。
__doapl函数,是标准库里的名字,上面的代码是从标准库里拿出来删减所得
return by reference 语法分析
传递者无需知道接收者是以什么(reference)形式接收
1
2
3
4
5
6
7
8
9
10
11
| inline complex&
__doapl(complex* ths,const complex& r)
{
...
return *ths;
}
inline complex&
complex::operator += (const complex& r)
{
return __doapl(this ,r);
}
|
那为了方便,反正使用函数之后也不用在乎返回值,把返回值类型设置为void可不可以呢?
不可以
当使用者这样使用时(c++允许连串赋值)
第一步c1加到c2的结果就不是无关紧要了,因为它需要作为右值参与下次计算。
class body之外的各种定义(definitions)
1
2
3
4
5
6
7
8
9
10
| inline double
imag(const complex& x)
{
return x.imag();
}
inline double
real(const complex& x)
{
return x,real();
}
|
1
2
3
4
5
6
| {
complex c1(2,1);
cout<<imag(c1);
cout<<real(c1);
}
|
operator overloading (操作符重载之二,非成员函数) 无this
为了应对client(客户)的三种可能用法,这里写了三个函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| inline complex
operator + (const complex& x,const complex& y)
{
return complex (real (x) + real (y),
imag (x) + imag (y) );
}
inline complex
operator + (const complex& x,double y)
{
return complex (real (x) + y,imag (x) );
}
inline complex
operator + (double x,complex& y)
{
return complex (x + real(y) ,imag (y) );
}
|
下面对应三种用法
1
2
3
4
5
6
7
| {
complex c1(2,1);
complex c2;
c2=c1+c2;
c2=c1+5;
c2=7+c1;
}
|
temp object(临时对象) typename();
上面三个加函数
绝对不能return by reference,
因为,他们返回的必定是一个local object.
和之前return一样,返回的东西是一个新创建的,函数结束时就会死亡,那么传递的引用就是错误的东西。
typename();表示创建一个临时对象,这个对象生命很短且没有名字,使用方法就是一个数据类型比如int后面跟一个小括号,括号里放给对象的内容。
在标准库里常用
operator overloading (操作符重载),非成员函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
inline bool
operator == (const complex& x,const complex& y)
{
return real (x)==real(y)&&imag(x)==imag(y);
}
inline bool
operator==(const complex& x,double y)
{
return real(x)==y&&imag(x)==0;
}
inline bool
operator ==(double x,const complex& y)
{
return x==real(y)&&imag(y)==0;
}
|
1
2
3
4
5
6
7
| {
complex c1(2,1);
complex c2;
cout<<(c1==c2);
cout<<(c1==2);
cout<<(0=c2);
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
| inline complex
conj (const complex& x)
{
return complex (real(x),-imag(x));
}
#include<iostream.h>
ostream&
operator <<(ostream& os,const complex& x)
{
return os<<'('<<real(x)<<','
<<imag(x)<<')';
}
|
1
2
3
4
5
| {
complex c1(2,1);
cout<<conj(c1);=>(2,1)
cout<<c1<<conj(c1);=>(2,1)(2,-1)
}
|
整理
- 构造函数用initaliazation list初值列(参数初始化表)
- 函数该不该加const
- 参数的传递尽量考虑pass by reference
- 数据要尽可能的放在private里,函数绝大部分要放在public里
- 防卫式声明
class 的两个经典分类
之前所记是无指针的
现在来写有指针的
1
2
3
4
5
6
7
8
9
10
11
12
|
int main()
{
String s1();
String s2("hello");
String s3(s1);
cout<<s3<<endl;
s3=s2;
cout<<s3<<endl;
}
|
三个特殊函数,有些书把三个新增函数叫做Big Three
1
2
3
4
5
6
7
8
9
10
11
| class String
{
public:
String(const char* cstr=0);
=>1 String(const String& str);
=>2 String& operator=(const String& str);
=>3 ~String();
char* get_c_str() const { return m_data; }
private:
char* m_adta;
};
|
ctro和dtor(构造函数和析构函数)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| inline
String::String(const char* cstr=0)
{
if(cstr){
m_adta=new char[strlen(cstr)+1];
strcpy(m_adta,cstr);
}
else{
m_data=new char[1];
*m_adta='/0';
}
}
inline
String::~String()
{
delete[] m_data;
}
|
class with pointer memeber 必须有copy ctor(copy constructor)和copy op= (copy assignment operator)
对于string类,他的对象中的数据只有一个指针,指针所指向的字符串是不属于data的
没有特地为带有指针的对象进行赋值时,就会出现两个指针指向同一个地址的情况,这很危险(因为修改其中任意一个都会将字符串修改,复制出来的指针原来指向的地址也不会被释放还会造成内存泄漏),这种叫做浅拷贝
1
2
3
4
5
6
| inline
String::String(const String& str)
{
m_adta =new char[strlen(str.m_data)+1];
strcpy(m_data,str,m_data);
}
|
1
2
3
4
5
|
{
String s1("Hello");
String s2(s1);
}
|
copy assignment operator(拷贝赋值函数)
1
2
3
4
5
6
7
8
9
10
| inline
String& String::operator=(const String& str)
{
if(this==&str)
return *this;
delete[] m_data;
m_data=new char[strlen(str.m_data)+1];
strcpy(m_data,str.m_data);
return *this;
}
|
这个检测自我赋值很重要(我觉得),虽然用到它需要你忘记了已经把两个指针指向了同一地址(这是可能发生的)
可以想一下,如果真的传入的参数所指向的地址和要被赋值的指针指向的地址相同,最开始为了防止内存泄露的delete一执行就全删掉了
output函数
1
2
3
4
5
6
| #include<iostream.h>
ostream& operator<<(ostream& os,const String& str)
{
os<<str.get_c_str();
return os;
}
|
1
2
3
4
| {
String s1("hello");
cout<<a1;
}
|
所谓stack(栈)、所谓heap(堆)
Stack,是存在某个作用域(scope)的一块内存空间(memory space)。例如当你调用函数,函数本身即会形成一个stack用来放置它所接收的参数,返回地址以及local object。(侯捷老师说,不完全是,除了函数之外还有其他的用到栈的地方)
在函数本身(function body)内声明的任何变量,其所使用的内存块都取自上述stack。
Heap,或称system heap,是指由操作系统提供的一块global内存空间,程序可动态分配(dynamic allocated)从中获得若干区块(blocks)。
1
2
3
4
5
6
| class Complex {...};
...
{
Complex c1(2,1);
Complex* p=new Complex(3);
}
|
stack objects(本地对象)的生命期
1
2
3
4
5
| class Complex {...}
...
{
Complex c1(1,2);
}
|
c1便是所谓的stack object,其生命在作用域(scope)结束时结束。
这种作用域内的object,又称为auto object,因为它会”自动“清理自己。
static local objects(静态本地对象)的生命期
1
2
3
4
5
| class Complex {...}
...
{
static Complex c2(1,2);
}
|
c2便是所谓static object,其生命在作用域(scope),结束之后仍然存在,直到整个程序结束。
global objects(全域/全局对象)的生命期
1
2
3
4
5
6
7
| class Complex {...}
...
Complex c3(1,2);
int main()
{
...
}
|
c3便是所谓的global object,其生命在整个程序结束之际才结束。可以把他设为一种static object,其作用域是“整个程序”。
heap object的生命期
1
2
3
4
5
6
7
8
9
|
class Complex {...}
...
{
Complex* p=new Complex;
...
delete p;
}
|
1
2
3
4
5
6
|
class Complex {...}
...
{
Complex* p=new Complex;
}
|
错误写法中没有写delete,会造成内存泄露
内存泄漏指你本来有一块内存,可是经过某些时间或某些作用域之后,你对他失去了控制
关于new和delete都可以在c++语法书里查到
new:先分配memory,再调用ctor(构造函数)
1
2
3
4
5
6
| Complex* pc=new Compelx(1.2);
Complex *pc;
void* mem=operator new(sizeof(Complex));
pc =static_cast<Compelx*>(mem);
pc->Complex::Complex(1,2);
|
delete:先调用dtor,再释放memory
1
2
3
4
5
6
| Complex* pc=new Compelx(1,2);
...
delete pc;
Complex::~Complex(pc);
operator delete(pc);
|
1
2
3
4
5
6
7
8
9
| class String
{
public:
~String()
{delete[] m_data;}
...
private:
char* m_data;
}
|
动态分配所得到的内存块(memory block),in vc(一种编译器)
以之前new一个复数为例,调试模式下分配的内存

一个复数,实部虚部两个double八个字节(应该是16字节,但是侯捷老师说是8个字节,咱们先按照8个来讲,可能是32位的要8字节吧)
但是动态分配给他的不止有八个字节
图中上部分灰色部分(一个是4字节)有4*8=32字节,首尾砖头颜色的是cookie(小甜饼干,先不说是干嘛的,一个四字节)4乘2=8。
所以动态分配一个复数会分配8+(32+4)+(4*2)=复数+灰色+红色=52,但是vc分配内存块一定是16的倍数(有原因,现在不说),所以就有了深绿色的部分(填充物),将分配的内存补充至十六的倍数64(离52最近的16的倍数)
这看起来很浪费内存,但是这是必要的,回收内存的时候需要这些东西
没有进入调试模式分pride动态内存是这样的
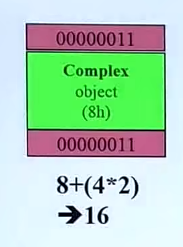
没有灰色部分(包括复数前面的八个和两侧的debug header)一定要加cookie,这是一定的。
8+(4*2)=16,正好是16的倍数,不需要加pad(填充)
cookie的作用:记住给你的整块的内存的大小,因为在delete的时候只知道一个指针,他不知道要回收多大,在写malloc和free在写的时候就规定好,在分配好的内存上头写一个cookie来确定大小。
注意:调试模式分配出去的内存大小是64=0x40,而cookie记录的是0x41,这是为什么?
最后那个bit是用来标记这块内存区域有没有被分配出去,0和1,0代表收回来,1代表给出去(这里感觉设计的好厉害)
对于非调试模式下的也同样(16=0x10)。
这里也解释了为什么分配出去的内存块大小一定是16的倍数,这样cookie的后四位就一定是0,可以借一位来表示内存是否属于操作系统
同样,String被分配内存时
调试模式

非调试模式
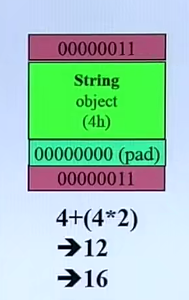
new 带有[]叫array new ,delete带有[]叫做array delete,array new要与array delete搭配使用,不然会出错
动态分配所得的array

8*3是三个复数(一个复数俩double),32+4是橙色(之前是灰色,debug header,非调试模式没有),4乘2是cookie,最后那个4(counter)是vc编译器的做法(别的不一定)用一个整数表示这里有几个东西(内容)
同理,String的
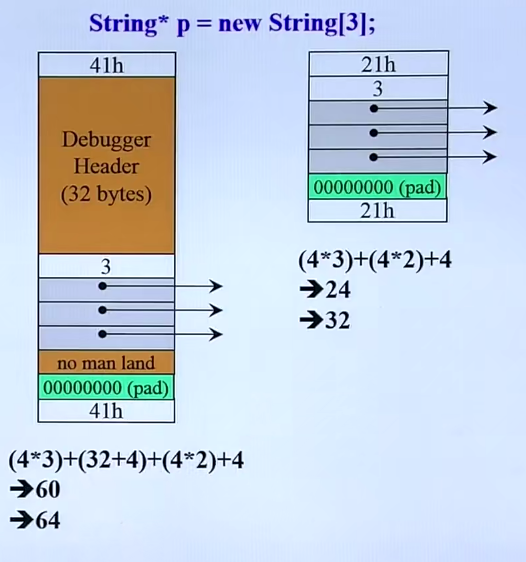
array new一定要搭配array delete
1
2
3
4
5
6
7
8
|
String* p=new String[3];
...
delete[] p;
String* p=new String[3];
...
delete p;
|
错误示范没有加[],第一个对象会被delete掉后面两个不会,后面两个就造成内存泄露了。
进一步扩充:static(静态)
在类的数据或者函数前,加上static,他就变成了静态成员或静态成员函数
加上static之后,数据就与类分离了,它没有this,存储在另一个地方(可以找到,我们不知道)
侯捷老师以银行账户体系为例子:创建出一百万个账户,其中利率与账户无关,这种情况下,就应该将利率设计为静态数据
静态函数同样没有this,不能处理其他普通的数据,只能处理静态的数据
1
2
3
4
5
6
7
8
9
10
11
| class Account{
public:
static double m_rate;
static void set_rata(const double& x) {m_adta =x;}
};
double Accout::m_rata=8.0;
int main() {
Account::set_rate(0.5);
Accout a;
a.set_rate(7.0);
}
|
进一步补充:把ctors放在private里
1
2
3
4
5
6
7
8
9
10
11
|
class A{
public:
static A& getInstance(return a;)
setup(){...}
private:
A();
A(const A& rhs);
static A a;
...
}
|
但是如果外界没有需要用到a的地方,就造成了浪费。所以有更好的写法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| ::getInstance().setup();class A {
public:
static A& getInstance();
setup();{...}
private:
A();
A(const A& rhs);
...
};
A& A::getInstance()
{
static A a;
return a;
}
|
进一步补充:cout
为什么cout可以接受那么多的类型?是因为重载了很多类型?是的
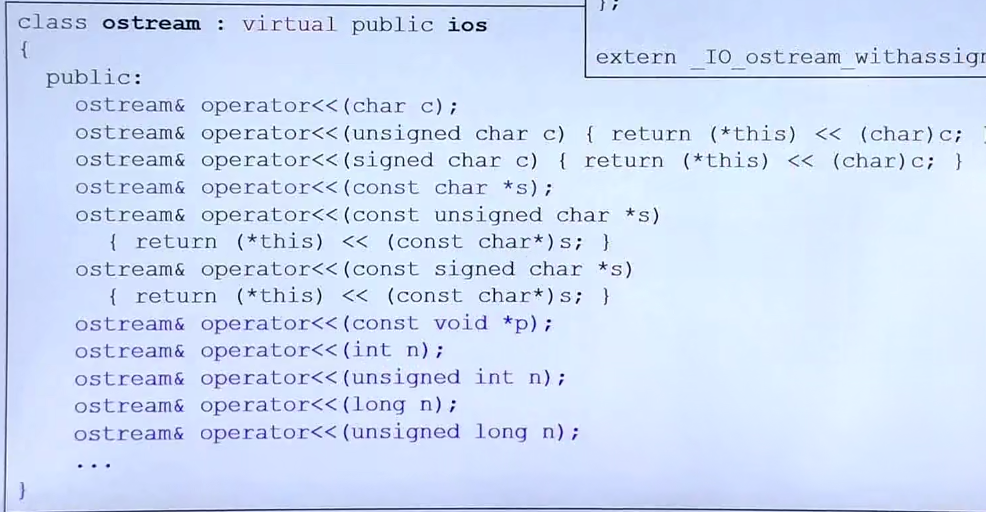
关于cout的定义
1
2
3
4
5
| class _IO_ostream_withassign
:public ostream{
。。。
};
extern _IO_ostream_withassign cout;
|
进一步补充: function template,函数模板
这里只是部分,
1
2
3
4
5
6
| template <calss T>
inline
const T& min(const T& a,const T& b)
{
return b<a?b:a;
}
|
1
2
| stone r1(2,3),r2(1,4),r3;
r3=min(r1,r2);
|
这样编译器就会将min中的T替换为stone去比较大小。
遇到小于号时(<)会去到stone里找有没有小于号的重载,如果有就执行,没有就报错
进一步扩充:namespace
using directive
1
2
3
4
5
6
7
8
| #include<iostream.h>
using namespace std;
int main()
{
cin<<...;
cout<<...;
return 0;
}
|
using declaration
1
2
3
4
5
6
7
8
| #include<iostream.h>
using std::cout;
int main()
{
std::cin<<...;
cout<<...;
return 0;
}
|
不开的
1
2
3
4
5
6
7
| #include<iostream.h>
int main()
{
std::cin<<...;
std::cout<<...;
return 0;
}
|
Composition(复合) ,表示has-a(有一个)
1
2
3
4
5
6
7
| template <class T,class Sequence =deque<T> >
class queue{
...
protected:
Sequence c;
public:
}
|
侯捷老师将他替换过来了//Sequence —–>deque<T>
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| template <class T>
class queue{
...
protected:
deque<T> c;
public:
bool empty()const{return c.empty();}
size_type size()const {return c.front();}
reference front(){return c.front();}
reference back(){return c,back();}
void push(const value_type& x){ c.push_back(x);}
void pop(){c.pop_front();}
};
|
一个类里面有另n个类,叫复合
老师说要学会用图的形式
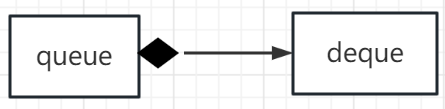
黑色菱形这一端就是容器,容纳了另外一个东西
这种写法叫做adapter,改造适配,这里queue就是adapter
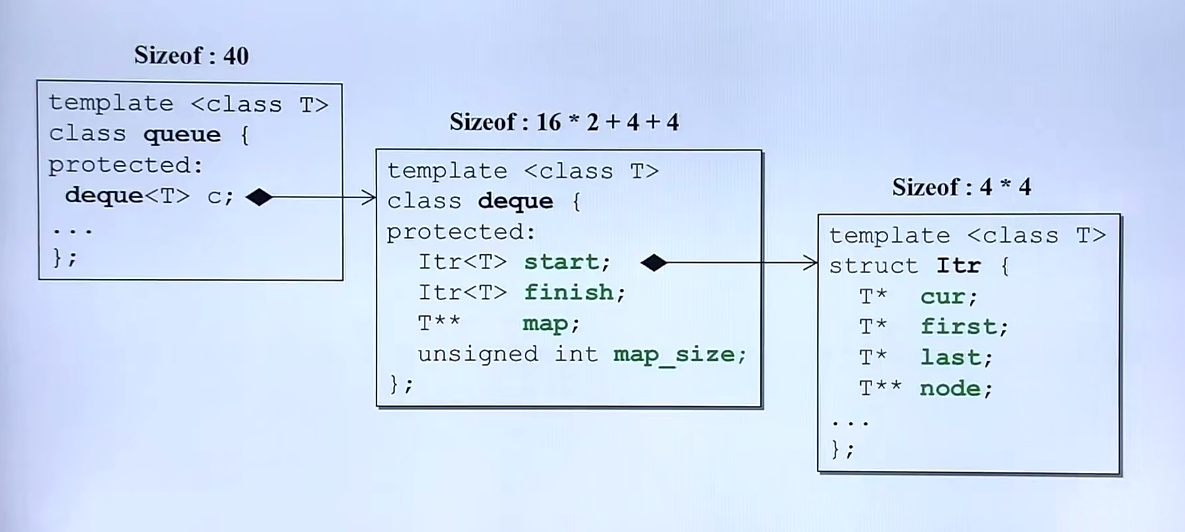
可以看到,在deque里也有两个adapter,可以看出大小上的关系
Composition(复合)关系下的构造和析构
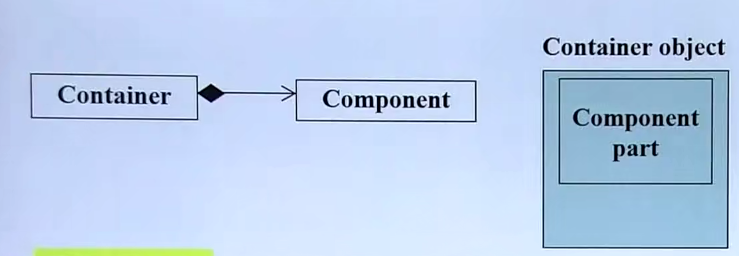
container是容器的意思,component是成分的意思
container一定大于等于component
构造要从内而外
container的构造函数首先调用component的default(默认)构造函数,然后才执行自己。
1
| Container::Container(...):Component(){...};
|
析构从外而内
container的析构函数首先执行自己,然后调用component的析构函数。
1
| Container::~Container(...){...~Component()};
|
Delegantion(委托).Composition by reference.
1
2
3
4
5
6
7
8
9
10
11
|
class StringRep;
class String{
public:
String();
String(const char *s);
String &operator=(const String& s);
...
private:
StringRep* rep;
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
#include "String.hpp"
namespace{
class StringRep{
friend class String;
StringRep(const char* s);
~StringRep();
int count;
char* rep;
};
}
String::String(){...}
...
|
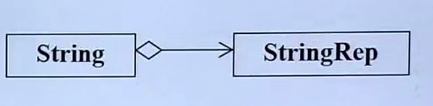
菱形没有涂黑表示关系指针指向(并不扎实,还没有拥有,不知到什么时候会拥有)
指针指向,他们的生命就不一样了
这个写法叫做point to implementation(有一根指针指向实现所有功能的类),另外一个名字handle/body(调用者是handle)
这跟指针可以指向任何一个类(又叫编译防火墙,每次修改只需修改类)
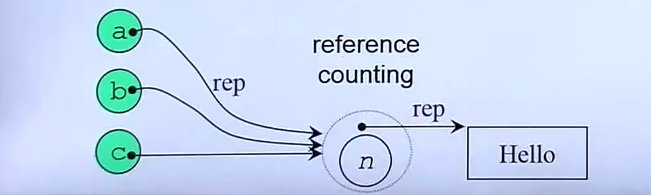
这是根据上面代码总结的图,reference counting(共享,有多个指针指向同一位置)
但是要注意的是:如果共享就不要轻易修改。解决方式也很简单,让要修改的位置copy一份修改。
inherited(继承),表示is-a(是一个)
1
2
3
4
5
6
7
8
9
10
11
| struct _List_code_bace
{
_List_code_base* _M_next;
_List_dode_base* _M_prev;
};
template<typename _Tp>
struct _List_node
:public _List_node
{
_TP _M_data;
};
|
inherited(继承)关系下的构造和析构
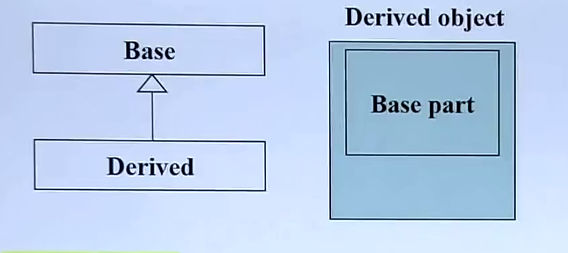
与Composition(复合)类似
构造由内而外
Derived的构造函数首先调用Base的defult的构造函数然后才执行自己。
1
| Derived::Derived(...):Base(){...}
|
析构由外而内
Derived的析构函数先执行自己,然后调用base 的析构函数。
1
| Derived::~Derived(...){... ~Base};
|
base calss的dtor必须是virtual,否则会出现undefined behavior(先放在这里,后面会说)
现在可以理解为一个良好的习惯,你认为你的class会变成一个父类,或者将来会成为一个父类,那就把析构函数设置成虚函数。
Inheritance(继承)with virtual functions(虚函数)
语法:在函数前加上virtual就变成虚函数
继承,数据可以继承,函数也可以继承,但是数据继承过来占用内存,那函数继承从内存角度怎么理解,不能从内存的角度去看,函数的继承其实继承的时调权。
non-virtal函数:你不希望derived class (子类)重新定义(override,覆写)它。这个override术语不能乱用,只能在虚函数被重新定义才能叫override。
virtual函数:你希望derived class 重新定义(override,覆写)它,且你对它已经有了默认定义。
pure virtual 纯虚函数:你希望derived class 一定要重新定义它,你对它没有默认定义。
1
2
3
4
5
6
7
8
9
| class Shape{
public:
virtual void draw()const=0;
virtual void error(const std::string& msg);
int objectID()const;
...
};
class Rectangle: public Shape{...};
class Ellipse:public Shape{...};
|
error的作用:当运行出错,可以调出是哪个图形的错误。
纯虚函数与空函数不同:纯虚函数要求子类必须覆写,而空函数即使子类不定义也会通过编译。
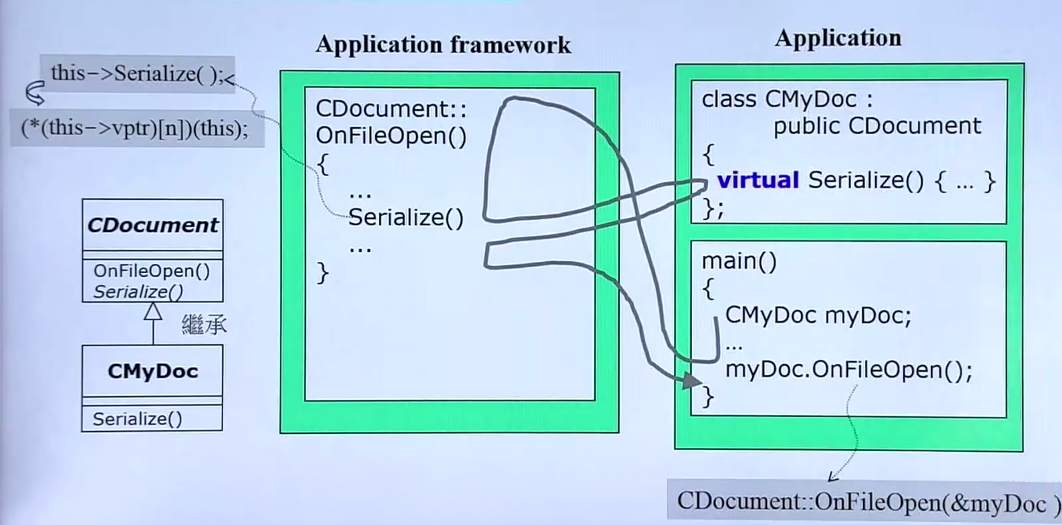
右边的上方是子类,下方是调用用例,左边是父类。
当主函数,调用myDoc.OnFileOpen();时会先去调用OnFileOpen函数,当执行到Serizalize时,会去找子类的补充定义(覆写)
主函数里写出了函数全名,括号里的参数是this指针(隐藏的不用写出来),而接下来调用内部的纯虚函数也是通过this指针(看左边的指出去的地方),this指针指向了子类里的定义的函数。
这个写法叫做template method (不是c++里的模板只是借用这个模板,在Java里method叫做函数)大名鼎鼎的23个设计模式之一
Inheritance+Composition关系下的构造和析构
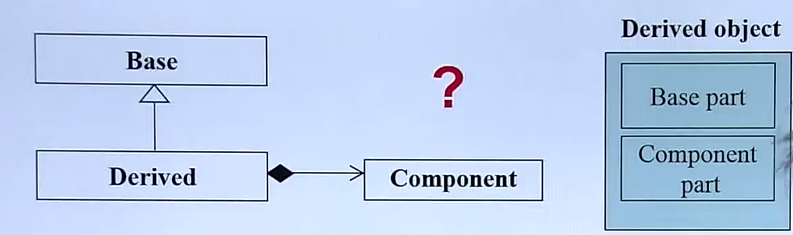
在内存中的存储方式谁上谁下对我们编程没多打影响。但是我们要知道当我们创建一个这样的(从父类继承,又和另一个类复合)对象时,构造函数的调用顺序是怎样的呢
老师把这个留给我们自己完成当然给了实验方法
各写三个类,构造函数打印一些内容(主要不要是一样的),根据先后顺序就可以直到先调用了谁
这是我写的test
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| #include<iostream>
using namespace std;
class base {
private:
int a;
public:
base()
{
cout << "base" << endl;
}
};
class component {
public:
component() { cout << "component" << endl; }
private:
int b;
};
class derived :public base{
public:
component b;
derived() { cout << "derived" << endl; }
};
int main()
{
derived a;
return 0;
}
|
附运行结果
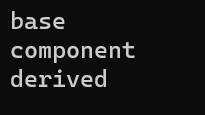
他是先调用了父类的构造函数,后调用复合类的构造函数
析构的时候呢
test修改如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| #include<iostream>
using namespace std;
class base {
private:
int a;
public:
base(){}
~base() { cout << "base" << endl; }
};
class component {
public:
component(){}
~component() { cout << "component" << endl; }
private:
int b;
};
class derived :public base {
public:
component b;
derived(){}
~derived() { cout << "derived" << endl; }
};
int main()
{
derived a;
return 0;
}
|
运行结果
就很好想了,先调用父类构造函数然后调用复合类的构造函数
1
2
3
4
5
| class Observer
{
public:
virtual void update(Subject* sub,int value)=0;
}
|
Delegantion(委托)+Inheritance(继承)
一个数据多个窗口观察(之前说的这个指针指向的模式用处不多,因为会因为任意一个修改
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| class Subjet
{
int m_value;
vetor<Observer*>m_views;
public:
void attach(Observer* obs)
{
m_view.push_back(obs);
}
void ste_val(int value)
{
m_value =value;
notify();
}
void notify()
{
for(int i=0;i<m_views.size();i++)
m_views[i]->update(this,m_value);
}
}
|
Delegantion(委托)+Inheritance(继承)续
Composite
我们要写一个文件系统(以此为例)
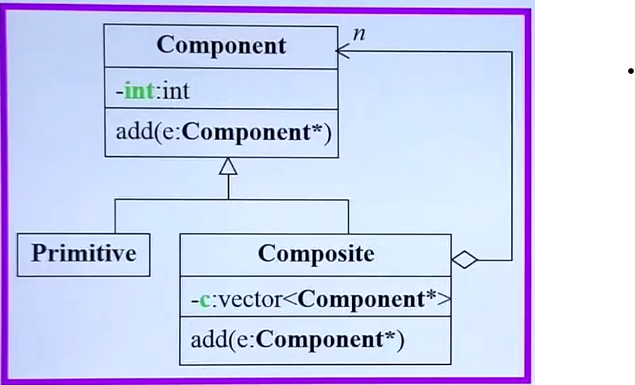
Primitive的意思是单体、基础物的意思
Composite(组合物)
两者同是conmponent的子类,右边使用了c++的容器,容器只可以存储一样大小的东西,所以对象不能直接放进去,这里用了指针
add函数(下右),既要加左边又要能加右边的类型。
这种叫Composite(23个模式之一)
1
2
3
4
5
6
7
| class Componst
{
int value;
public:
Component(int cal){value=val;}
virtual void add(Component*){}
};
|
Prototype(一种设计模型),想要创建未来出现的子类(不太理解)
需要每个将要创建的子类先自己创建一个自己的蓝本(原型)让框架去有办法看到原型,复制他创建它(一点没懂)
画图的时候先写object名字,再写typename

有下划线的是静态函数,带负号的是私有函数,带#的是protected函数,
LandSatImage()是私有的构造函数(但是是自己调用自己所以可以被调用)(我们用它调用addprototype把自己传到框架里)
调用父类的addProtetype将this作为参数,也就是将自己创建一份传到父类。
所有子类(未来的)还需要准备clone函数(克隆)就是new一个自己(自己写的),这样做出了一个副本,是在父类里使用刚才传过去的原型调用这个克隆函数。(父类有这个函数的纯虚函数)
如果没有原型,就不能调用clone函数,但是将clone设置成静态也能调用它?
调用静态需要classname,但是我们不知道calssname(未来的东西)
对于这种方式:写一个静态函数调用自己,又要写一个克隆自己的函数,这样产生的开销合理吗?
合理,为了使用别人写好的框架,需要让别人知道自己写的是什么(不太理解。。)